Topic Modeling without Prior#
Overview#
Topic modeling without prior is a crucial step in understanding the underlying topics in a corpus of text without any preconceived notions or biases. In the context of this research, the Latent Dirichlet Allocation (LDA) model is used to uncover the hidden thematic structure in the Cambodian news articles.
Configuration Details#
Model Type and Parameters#
The model used is LDA, with the following hyperparameters:
Number of Topics (k): 20
Alpha: 0.1
Eta: 0.01
These hyperparameters control the distribution of topics over documents (Alpha) and the distribution of words over topics (Eta).
Corpus Configuration#
The corpus is configured to include n-grams up to a maximum length of 3, with a minimum frequency of 20 and a minimum document frequency of 10. The text column used for modeling is ‘adjnouns’, focusing on adjectives and nouns.
Word Cloud Visualization#
The configuration also includes settings for generating word cloud visualizations for the topics. The word clouds are configured with the following properties:
Background Color: Black
Colormap: PuBu
Width: 400
Height: 200
Batch Configuration#
The batch configuration controls the execution environment, including the device (CPU), number of devices, and number of workers. It also specifies the paths for the configuration files and the output directory.
Execution Workflow#
Load Dataset: The dataset is loaded from the specified Parquet file containing the tokenized text.
Train LDA Model: The LDA model is trained on the corpus using the specified hyperparameters.
Evaluate Coherence: The coherence of the topics is evaluated using metrics such as U-Mass, C-UCI, C-NPMI, and C-V.
Generate Word Clouds: Word clouds are generated for the top words in each topic, providing a visual representation of the topics.
Inference (Optional): The model can be used to infer topics on new or unseen data.
Running the Workflow#
The entire workflow can be executed using the following command:
!nbcpu +workflow=nbcpu tasks='[nbcpu-topic_noprior]' mode=__info__
Show code cell output
[2023-08-15 17:05:23,109][hyfi.joblib.joblib][INFO] - initialized batcher with <hyfi.joblib.batch.batcher.Batcher object at 0x7f19e0456880>
[2023-08-15 17:05:23,110][hyfi.main.config][INFO] - HyFi project [nbcpu] initialized
[2023-08-15 17:05:23,298][hyfi.main.main][INFO] - The HyFI config is not instantiatable, running HyFI task with the config
[2023-08-15 17:05:24,126][hyfi.joblib.joblib][INFO] - initialized batcher with <hyfi.joblib.batch.batcher.Batcher object at 0x7f19e0065c10>
[2023-08-15 17:05:25,269][hyfi.task.batch][INFO] - Initalized batch: corpus(1) in /home/yjlee/workspace/projects/nbcpu/workspace/topic/corpus
[2023-08-15 17:05:26,715][hyfi.task.batch][INFO] - Initalized batch: corpus(1) in /home/yjlee/workspace/projects/nbcpu/workspace/topic/corpus
[2023-08-15 17:05:26,716][hyfi.task.batch][INFO] - Initalized batch: model(0) in /home/yjlee/workspace/projects/nbcpu/workspace/topic/model
[2023-08-15 17:05:27,425][hyfi.task.batch][INFO] - Initalized batch: corpus(1) in /home/yjlee/workspace/projects/nbcpu/workspace/topic/corpus
[2023-08-15 17:05:29,188][hyfi.batch.batch][INFO] - Setting seed to 165648969
[2023-08-15 17:05:29,188][hyfi.batch.batch][INFO] - Init batch - Batch name: model, Batch num: 0
[2023-08-15 17:05:29,989][hyfi.task.batch][INFO] - Initalized batch: corpus(3) in /home/yjlee/workspace/projects/nbcpu/workspace/nbcpu-topic_noprior/corpus
[2023-08-15 17:05:29,989][hyfi.batch.batch][INFO] - Init batch - Batch name: model, Batch num: 6
[2023-08-15 17:05:29,989][hyfi.task.batch][INFO] - Initalized batch: model(6) in /home/yjlee/workspace/projects/nbcpu/workspace/nbcpu-topic_noprior/model
[2023-08-15 17:05:30,782][hyfi.task.batch][INFO] - Initalized batch: corpus(1) in /home/yjlee/workspace/projects/nbcpu/workspace/topic/corpus
[2023-08-15 17:05:30,782][hyfi.task.batch][INFO] - Initalized batch: runner(3) in /home/yjlee/workspace/projects/nbcpu/workspace/nbcpu-topic_noprior/runner
[2023-08-15 17:05:30,782][hyfi.workflow.workflow][INFO] - Running task [nbcpu-topic_noprior] with [run={} verbose=False uses='nbcpu-topic_noprior']
0%| | 0/1 [00:00<?, ?it/s][2023-08-15 17:05:30,784][thematos.datasets.corpus][INFO] - Loading corpus...
[2023-08-15 17:05:30,785][thematos.datasets.corpus][INFO] - Processing documents in the column 'adjnouns'...
[2023-08-15 17:05:34,442][hyfi.utils.iolibs][INFO] - Loaded the file: /home/yjlee/workspace/projects/nbcpu/tests/assets/stopwords/nbcpu-topic.txt, No. of words: 21
[2023-08-15 17:05:34,442][hyfi.utils.iolibs][INFO] - Remove duplicate words, No. of words: 21
[2023-08-15 17:05:34,442][lexikanon.stopwords.stopwords][INFO] - Loaded 21 stopwords from /home/yjlee/workspace/projects/nbcpu/tests/assets/stopwords/nbcpu-topic.txt
[2023-08-15 17:05:34,442][lexikanon.stopwords.stopwords][INFO] - Loaded 21 stopwords
[2023-08-15 17:06:12,690][thematos.datasets.corpus][INFO] - Total 39637 documents are loaded.
[2023-08-15 17:06:33,336][hyfi.utils.datasets.save][INFO] - Saving dataframe to /home/yjlee/workspace/projects/nbcpu/workspace/nbcpu-topic_noprior/corpus/corpus_doc_ids.parquet
[2023-08-15 17:06:33,368][hyfi.composer.config][INFO] - Saving config to /home/yjlee/workspace/projects/nbcpu/workspace/nbcpu-topic_noprior/corpus/configs/corpus(3)_config.json
[2023-08-15 17:06:33,369][hyfi.composer.config][INFO] - Saving config to /home/yjlee/workspace/projects/nbcpu/workspace/nbcpu-topic_noprior/corpus/configs/corpus(3)_config.yaml
[2023-08-15 17:06:35,336][thematos.models.lda][INFO] - Number of docs: 39637
[2023-08-15 17:06:35,336][thematos.models.lda][INFO] - Vocab size: 24764
[2023-08-15 17:06:35,336][thematos.models.lda][INFO] - Number of words: 7206156
[2023-08-15 17:06:35,336][thematos.models.lda][INFO] - Removed top words: []
[2023-08-15 17:06:35,336][thematos.models.lda][INFO] - Training model by iterating over the corpus 100 times, 10 iterations at a time with 0 workers
0%| | 0/10 [00:00<?, ?it/s][2023-08-15 17:06:39,356][thematos.models.lda][INFO] - Iteration: 0 Log-likelihood: -9.56337265225683
10%|████▍ | 1/10 [00:04<00:36, 4.04s/it][2023-08-15 17:06:43,295][thematos.models.lda][INFO] - Iteration: 10 Log-likelihood: -9.144156799923582
20%|████████▊ | 2/10 [00:07<00:31, 3.98s/it][2023-08-15 17:06:47,272][thematos.models.lda][INFO] - Iteration: 20 Log-likelihood: -8.979668309579871
30%|█████████████▏ | 3/10 [00:11<00:27, 3.98s/it][2023-08-15 17:06:51,308][thematos.models.lda][INFO] - Iteration: 30 Log-likelihood: -8.875918495887053
40%|█████████████████▌ | 4/10 [00:15<00:24, 4.00s/it][2023-08-15 17:06:55,122][thematos.models.lda][INFO] - Iteration: 40 Log-likelihood: -8.807991873686014
50%|██████████████████████ | 5/10 [00:19<00:19, 3.93s/it][2023-08-15 17:06:58,964][thematos.models.lda][INFO] - Iteration: 50 Log-likelihood: -8.758273433104282
60%|██████████████████████████▍ | 6/10 [00:23<00:15, 3.90s/it][2023-08-15 17:07:02,810][thematos.models.lda][INFO] - Iteration: 60 Log-likelihood: -8.722993516418107
70%|██████████████████████████████▊ | 7/10 [00:27<00:11, 3.88s/it][2023-08-15 17:07:06,473][thematos.models.lda][INFO] - Iteration: 70 Log-likelihood: -8.695350780812172
80%|███████████████████████████████████▏ | 8/10 [00:31<00:07, 3.81s/it][2023-08-15 17:07:09,944][thematos.models.lda][INFO] - Iteration: 80 Log-likelihood: -8.674064501996195
90%|███████████████████████████████████████▌ | 9/10 [00:34<00:03, 3.71s/it][2023-08-15 17:07:13,307][thematos.models.lda][INFO] - Iteration: 90 Log-likelihood: -8.656676192642903
100%|███████████████████████████████████████████| 10/10 [00:37<00:00, 3.80s/it]
<Basic Info>
| LDAModel (current version: 0.12.5)
| 39637 docs, 7206156 words
| Total Vocabs: 177295, Used Vocabs: 24764
| Entropy of words: 8.14474
| Entropy of term-weighted words: 8.96706
| Removed Vocabs: <NA>
|
<Training Info>
| Iterations: 100, Burn-in steps: 0
| Optimization Interval: 10
| Log-likelihood per word: -8.65668
|
<Initial Parameters>
| tw: TermWeight.IDF
| min_cf: 10 (minimum collection frequency of words)
| min_df: 10 (minimum document frequency of words)
| rm_top: 0 (the number of top words to be removed)
| k: 20 (the number of topics between 1 ~ 32767)
| alpha: [0.1] (hyperparameter of Dirichlet distribution for document-topic, given as a single `float` in case of symmetric prior and as a list with length `k` of `float` in case of asymmetric prior.)
| eta: 0.01 (hyperparameter of Dirichlet distribution for topic-word)
| seed: 165648969 (random seed)
| trained in version 0.12.5
|
<Parameters>
| alpha (Dirichlet prior on the per-document topic distributions)
| [0.04001153 0.03526779 0.03648445 0.05125729 0.0339137 0.02823607
| 0.03101887 0.06172507 0.01710778 0.05294487 0.03747123 0.02802146
| 0.03800969 0.04706813 0.03247076 0.04857473 0.03060325 0.02949386
| 0.04723632 0.0597007 ]
| eta (Dirichlet prior on the per-topic word distribution)
| 0.01
|
<Topics>
| #0 (382083) : military trump myanmar north_korea chinese nuclear united_state washington trade beijing japan south war sea sanction taiwan foreign bangladesh security philippine
| #1 (325901) : digital technology company internet online service huawei mobile user platform customer data app business startup network smart payment e-commerce tech
| #2 (370817) : russia trump ukraine russian putin european britain europe germany republican moscow war brexit israel turkey sanction state ukrainian deal vote
| #3 (378769) : water city road river tourist village province area resident siem_reap boat waste bus house angkor phnom_penh restaurant temple construction site
| #4 (348318) : party election political cpp opposition cnrp democracy prime_minister cambodian human_right government hun_sen rainsy law cambodia leader peace hun khmer_rouge national_assembly
| #5 (164841) : india indian pakistan australia modi iran australian tobacco afghanistan hiv refugee taliban new_delhi sri_lanka saudi afghan saudi_arabia state brazil attack
| #6 (287468) : property company real_estate investor market csx project construction developer port investment price sale share firm ipo hong_kong buyer bond revenue
| #7 (601260) : global world economic development challenge policy system region climate_change sustainable strategy future international change action social approach crisis security need
| #8 (171616) : rice farmer agriculture food agricultural tonne fish production crop fishery price export ton cassava vegetable market product rubber farm une
| #9 (553151) : asean cooperation cambodia trade minister chinese vietnam meeting regional development region bilateral relation rcep tourism japan visit economic agreement cambodian
| #10 (380564) : covid-19 health vaccine case tourism virus tourist airline flight pandemic vaccination infection outbreak hospital omicron disease medical patient travel coronavirus
| #11 (254731) : game club football sport team player season league match athlete champion fan stadium tournament world_cup coach premier_league sea_game final minute
| #12 (319822) : police court victim drug prison district judge suspect money provincial case commune phnom_penh crime riel municipal arrest woman complaint lawyer
| #13 (302899) : art film artist music book life story street history museum father khmer_rouge thing kim culture friend family malaysia muslim show
| #14 (365010) : bank loan banking nbc customer insurance financial payment riel currency credit cambodia deposit service financial_institution branch transaction commercial account plc
| #15 (437692) : student child education school woman programme skill university youth teacher young scholarship training program cambodia cambodian family event community award
| #16 (226136) : land ministry forest province authority law provincial government ngo community commune wildlife environment mine official najib administration area national minister
| #17 (226055) : energy electricity adb project solar power climate oil green coal emission gas fuel renewable_energy plant supply development climate_change cambodia household
| #18 (533641) : inflation market growth price economy rate index dollar currency low stock central_bank debt analyst high fed bank data share global
| #19 (575382) : tax worker cambodia export sector factory business investment trade labour industry garment product government enterprise ministry smes law job union
|
[2023-08-15 17:07:17,226][thematos.models.base][INFO] - ==== Coherence : u_mass ====
[2023-08-15 17:07:17,227][thematos.models.base][INFO] - Average: -1.8225879015599518
[2023-08-15 17:07:17,227][thematos.models.base][INFO] - Per Topic: [-1.7071110993560232, -1.8081845262829659, -1.9131969426555329, -1.811269795871564, -1.3498192320627342, -3.6912594260915204, -2.107448523708784, -1.5613924125327066, -1.7372444610161113, -1.2590741935951324, -1.987925993990261, -1.7684996986493575, -1.6468222499235743, -1.8500283847239365, -1.762784460925799, -1.7677539558873556, -1.7047070441749212, -2.095960403158903, -1.4203746205291528, -1.500900606062698]
[2023-08-15 17:07:19,494][thematos.models.base][INFO] - ==== Coherence : c_uci ====
[2023-08-15 17:07:19,494][thematos.models.base][INFO] - Average: 1.0290000781633546
[2023-08-15 17:07:19,494][thematos.models.base][INFO] - Per Topic: [0.8846061521441189, 1.4163701471052752, 1.2353016988971701, 1.1061697342330765, 1.4993583851860008, -1.7158872630061799, 0.7693377098738617, 0.5218923677913766, 2.002831510850781, 0.46210398687947474, 0.7581604351451704, 2.2781620212723417, 1.9218682460540089, 1.429650347371691, 1.222235377414929, 1.4120445604430085, 0.6236365491622836, 1.2744142344769005, 1.1367955585912328, 0.3409498033805712]
[2023-08-15 17:07:21,940][thematos.models.base][INFO] - ==== Coherence : c_npmi ====
[2023-08-15 17:07:21,940][thematos.models.base][INFO] - Average: 0.13420203630003497
[2023-08-15 17:07:21,940][thematos.models.base][INFO] - Per Topic: [0.10735044089151692, 0.16965737425944216, 0.1473561039724611, 0.13021031021718948, 0.19018021260943738, -0.015063386206600554, 0.10214679442049843, 0.06938342508611049, 0.22812465841815108, 0.06926619686808591, 0.10172751391793497, 0.25444843275076423, 0.22586250026539234, 0.14509603937295965, 0.16011320009893742, 0.1765525283148321, 0.07502636700932833, 0.14680306438121216, 0.14759230757004674, 0.05220664178299874]
[2023-08-15 17:07:55,167][thematos.models.base][INFO] - ==== Coherence : c_v ====
[2023-08-15 17:07:55,168][thematos.models.base][INFO] - Average: 0.7397635974735023
[2023-08-15 17:07:55,168][thematos.models.base][INFO] - Per Topic: [0.7337397843599319, 0.7812566518783569, 0.8287632763385773, 0.7284845173358917, 0.7675876900553703, 0.6177206009626388, 0.7108045041561126, 0.6586671024560928, 0.8340025961399078, 0.6441118210554123, 0.6904611855745315, 0.8438107550144196, 0.785612553358078, 0.7714586138725281, 0.810454261302948, 0.7887740135192871, 0.6361881583929062, 0.7001782149076462, 0.808130270242691, 0.6550653785467148]
[2023-08-15 17:07:55,312][thematos.models.base][INFO] - Model saved to /home/yjlee/workspace/projects/nbcpu/workspace/nbcpu-topic_noprior/model/models/LDA_model(6)_k(20).mdl
[2023-08-15 17:07:55,399][hyfi.utils.datasets.save][INFO] - Saving dataframe to /home/yjlee/workspace/projects/nbcpu/workspace/nbcpu-topic_noprior/model/outputs/LDA_model(6)_k(20)-ll_per_word.csv
[2023-08-15 17:07:55,401][hyfi.utils.datasets.save][INFO] - >> elapsed time to save data: 0:00:00.001868
[2023-08-15 17:07:55,802][thematos.models.base][INFO] - Log-likelihood per word plot saved to /home/yjlee/workspace/projects/nbcpu/workspace/nbcpu-topic_noprior/model/outputs/LDA_model(6)_k(20)-ll_per_word.png
[2023-08-15 17:07:55,898][thematos.models.base][INFO] - ==== Document-Topic Distributions ====
[2023-08-15 17:07:55,898][thematos.models.base][INFO] - id topic0 topic1 ... topic17 topic18 topic19
39632 48187 0.669679 0.000036 ... 0.011932 0.000048 0.058952
39633 48132 0.069668 0.000039 ... 0.000033 0.000052 0.059065
39634 48115 0.000111 0.000098 ... 0.000082 0.000131 0.681714
39635 48085 0.000037 0.543615 ... 0.000027 0.000044 0.000055
39636 48087 0.000106 0.000093 ... 0.000078 0.000125 0.000158
[5 rows x 21 columns]
[2023-08-15 17:07:55,927][hyfi.utils.datasets.save][INFO] - Saving dataframe to /home/yjlee/workspace/projects/nbcpu/workspace/nbcpu-topic_noprior/model/outputs/LDA_model(6)_k(20)-doc_topic_dists.parquet
[2023-08-15 17:07:56,156][hyfi.utils.datasets.save][INFO] - >> elapsed time to save data: 0:00:00.228368
[2023-08-15 17:07:56,156][thematos.models.base][INFO] - ==== Topic-Word Distributions ====
[2023-08-15 17:07:56,163][thematos.models.base][INFO] - cambodia government ... sinan_chairman planning_construction
15 0.004534 0.000712 ... 6.901873e-09 6.901873e-09
16 0.002654 0.004698 ... 1.318271e-08 1.318271e-08
17 0.004470 0.003312 ... 1.327619e-08 1.327619e-08
18 0.000122 0.000938 ... 5.694903e-09 5.694903e-09
19 0.007558 0.004678 ... 1.506013e-05 6.056809e-09
[5 rows x 24764 columns]
[2023-08-15 17:07:56,278][hyfi.utils.datasets.save][INFO] - Saving dataframe to /home/yjlee/workspace/projects/nbcpu/workspace/nbcpu-topic_noprior/model/outputs/LDA_model(6)_k(20)-topic_term_dists.parquet
[2023-08-15 17:07:59,551][hyfi.utils.datasets.save][INFO] - >> elapsed time to save data: 0:00:03.272927
[2023-08-15 17:07:59,595][hyfi.utils.iolibs][INFO] - Save the list to the file: /home/yjlee/workspace/projects/nbcpu/workspace/nbcpu-topic_noprior/model/outputs/LDA_model(6)_k(20)-used_vocab.txt, no. of words: 24764
[2023-08-15 17:07:59,618][hyfi.utils.iolibs][INFO] - Save the list to the file: /home/yjlee/workspace/projects/nbcpu/workspace/nbcpu-topic_noprior/model/outputs/LDA_model(6)_k(20)-topic_top_words.txt, no. of words: 763
[2023-08-15 17:07:59,619][hyfi.utils.datasets.save][INFO] - Saving dataframe to /home/yjlee/workspace/projects/nbcpu/workspace/nbcpu-topic_noprior/model/outputs/LDA_model(6)_k(20)-topic_top_words_dists.csv
[2023-08-15 17:07:59,622][hyfi.utils.datasets.save][INFO] - >> elapsed time to save data: 0:00:00.002545
[2023-08-15 17:08:13,463][thematos.models.base][INFO] - Making wordcloud collage with titles: ['Topic 0', 'Topic 1', 'Topic 2', 'Topic 3', 'Topic 4', 'Topic 5', 'Topic 6', 'Topic 7', 'Topic 8', 'Topic 9', 'Topic 10', 'Topic 11', 'Topic 12', 'Topic 13', 'Topic 14', 'Topic 15', 'Topic 16', 'Topic 17', 'Topic 18', 'Topic 19']
[2023-08-15 17:08:13,464][hyfi.graphics.collage][INFO] - Making page 1/1 with 20 images
[2023-08-15 17:08:13,464][hyfi.graphics.collage][INFO] - Page titles: ['Topic 0', 'Topic 1', 'Topic 2', 'Topic 3', 'Topic 4', 'Topic 5', 'Topic 6', 'Topic 7', 'Topic 8', 'Topic 9', 'Topic 10', 'Topic 11', 'Topic 12', 'Topic 13', 'Topic 14', 'Topic 15', 'Topic 16', 'Topic 17', 'Topic 18', 'Topic 19']
[2023-08-15 17:08:13,464][hyfi.graphics.collage][INFO] - Page output file: /home/yjlee/workspace/projects/nbcpu/workspace/nbcpu-topic_noprior/model/outputs/wordcloud_collage/LDA_model(6)_k(20)_wordcloud_00.png
[2023-08-15 17:08:20,427][hyfi.graphics.utils][INFO] - Saved subplots to /home/yjlee/workspace/projects/nbcpu/workspace/nbcpu-topic_noprior/model/outputs/wordcloud_collage/LDA_model(6)_k(20)_wordcloud_00.png
[2023-08-15 17:08:20,428][thematos.models.base][WARNING] - pyLDAvis is not installed. Please install it to save LDAvis.
[2023-08-15 17:08:20,459][thematos.models.base][INFO] - Model summary saved to /home/yjlee/workspace/projects/nbcpu/workspace/nbcpu-topic_noprior/model/outputs/model-summary.jsonl
[2023-08-15 17:08:20,460][hyfi.composer.config][INFO] - Saving config to /home/yjlee/workspace/projects/nbcpu/workspace/nbcpu-topic_noprior/model/configs/model(6)_config.json
[2023-08-15 17:08:20,460][hyfi.composer.config][INFO] - Saving config to /home/yjlee/workspace/projects/nbcpu/workspace/nbcpu-topic_noprior/model/configs/model(6)_config.yaml
100%|████████████████████████████████████████████| 1/1 [02:49<00:00, 169.70s/it]
[2023-08-15 17:08:20,485][thematos.runners.topic][INFO] - Saved summaries to /home/yjlee/workspace/projects/nbcpu/workspace/nbcpu-topic_noprior/runner(3)_summaries.json
[2023-08-15 17:08:20,486][hyfi.composer.config][INFO] - Saving config to /home/yjlee/workspace/projects/nbcpu/workspace/nbcpu-topic_noprior/runner/configs/runner(3)_config.json
[2023-08-15 17:08:20,486][hyfi.composer.config][INFO] - Saving config to /home/yjlee/workspace/projects/nbcpu/workspace/nbcpu-topic_noprior/runner/configs/runner(3)_config.yaml
Coherence Values and Selection of k#
The selection of the optimal number of topics (k) is a critical step in topic modeling, especially in Latent Dirichlet Allocation (LDA). This process involves evaluating the coherence of the topics generated for different values of k and selecting the one that maximizes coherence. In this analysis, we examine four different models with k values of 10, 20, 30, and 40. We evaluate the coherence using four different metrics: U-Mass, C-UCI, C-NPMI, and C-V. The results are plotted to visually assess the optimal k value in Fig. 3.
The following table summarizes the coherence values for each model:
k |
U-Mass |
C-UCI |
C-NPMI |
C-V |
|---|---|---|---|---|
10 |
-1.6788 |
0.6621 |
0.0936 |
0.6675 |
20 |
-2.1309 |
0.7761 |
0.1226 |
0.7350 |
30 |
-2.0985 |
0.9463 |
0.1385 |
0.7349 |
40 |
-2.4415 |
0.7213 |
0.1351 |
0.7603 |
Selecting the Appropriate k#
Based on the plot and the coherence values, the optimal k can be selected. Generally, the value of k that maximizes the coherence value is considered optimal. However, the choice might vary depending on the specific coherence metric used and the interpretability of the topics.
The selection of k is a nuanced process that depends on both quantitative metrics and qualitative assessment. While coherence values provide a quantitative measure, the interpretability and relevance of the topics should also be considered. It might be beneficial to examine the actual topics generated for the selected k and assess their relevance to the domain of interest.
Here, we select k = 20 as the optimal number of topics. The topics generated for this model are examined in the next section.
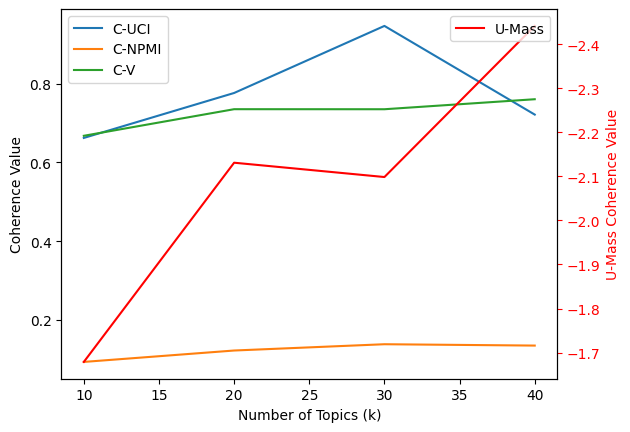
Fig. 3 Coherence values for different k values#
Model Results#
The Latent Dirichlet Allocation (LDA) model was applied to a corpus of 39,637 documents, resulting in the identification of 20 distinct topics. The model’s coherence scores and detailed topic-word distributions provide insights into the underlying themes within the corpus.
Topics Identification: The 20 topics identified represent distinct themes within the corpus. For example:
Topic 0: Focused on political themes, indicating a substantial portion of the corpus may be related to political discourse.
Topic 1: Centered on health and the COVID-19 pandemic, reflecting the global relevance of health issues.
Document-Topic Distributions: The distribution of topics within documents provides a granular view of the corpus’s thematic structure. This can be valuable for content categorization, recommendation systems, or understanding the evolution of themes over time.
Visualizations: The word cloud collages offer a visual representation of the topics, aiding in the intuitive understanding of the main themes. This can be particularly useful for communicating results to non-technical stakeholders.
Fig. 4 shows the wordcloud of the top 500 words in each topic from the LDA model with 20 topics. The size of the word is proportional to the frequency of the word in the topic.

Fig. 4 Wordcloud of the top 500 words in each topic from the LDA model with 20 topics. The size of the word is proportional to the frequency of the word in the topic.#
Topic Interpretation#
The following interpretation analyzes 20 topics extracted from a corpus of documents using Latent Dirichlet Allocation (LDA). These topics encompass a wide range of subjects, including politics, health, environment, technology, economy, culture, and international relations. The interpretation of each topic provides insights into the thematic structure of the corpus, reflecting societal, cultural, economic, and political dimensions. The analysis concludes with alternative considerations that could lead to a more nuanced understanding of the topics.
Topic #0: Focuses on political dynamics, including elections, legal matters, human rights, corruption, and governance. It reflects the political landscape and the struggle for democracy and justice.
Topic #1: Centers on the global health crisis, specifically COVID-19, its impact, vaccination efforts, and medical responses to the pandemic.
Topic #2: Addresses environmental and rural issues, such as water management, land use, farming, and community living. It may indicate concerns about sustainability and local livelihoods.
Topic #3: Highlights Cambodia’s social development, women’s issues, poverty alleviation, tourism, and governmental policies. It reflects a focus on national growth and societal well-being.
Topic #4: Emphasizes regional cooperation within ASEAN, international relations, economic development, and security matters. It suggests a focus on diplomacy and global interconnectedness.
Topic #5: Pertains to economic indicators, market trends, inflation, currency, and investment. It reflects the financial landscape and economic health.
Topic #6: Focuses on geopolitical tensions, specifically involving Russia, Ukraine, and related international conflicts and sanctions. It may indicate global power dynamics and diplomatic challenges.
Topic #7: Concerns trade, labor, and industry, including exports, tariffs, labor rights, and agreements. It reflects the dynamics of the global supply chain and workforce.
Topic #8: Centers on energy, technology, and environmental sustainability, including renewable energy, climate change, and technological innovation.
Topic #9: Highlights cultural aspects, including arts, entertainment, food, and urban lifestyle. It reflects cultural richness and societal engagement.
Topic #10: Focuses on education, youth development, skills training, and family dynamics. It may indicate a societal emphasis on education and personal growth.
Topic #11: Pertains to sports, entertainment, and aviation, reflecting leisure activities, competitions, and travel.
Topic #12: Addresses law enforcement, crime, traffic, and legal proceedings. It reflects societal order and legal matters.
Topic #13: Focuses on South Asian history, politics, and cultural connections, including India, Pakistan, Bangladesh, and Myanmar.
Topic #14: Highlights tourism, investment, agriculture, and infrastructure development, reflecting economic growth sectors.
Topic #15: Concerns banking, financial services, digital transactions, and business operations. It reflects the financial infrastructure and modern banking trends.
Topic #16: Focuses on Britain’s international relations, Brexit, business deals, and connections with Australia and Hong Kong.
Topic #17: Centers on digital platforms, online services, internet companies, and digital branding. It reflects the digital economy and technological advancements.
Topic #18: Addresses U.S. politics, military matters, nuclear issues, and international relations, reflecting global power dynamics.
Topic #19: Focuses on Southeast Asian politics and relations, including Malaysia, Indonesia, the Philippines, and related regional matters.
Filtering Topics for the Second Stage of the Analysis#
In the second stage of the research, the focus is on refining the analysis of central bank policy uncertainty in Cambodia’s highly dollarized economy by filtering out specific unrelated topics. The exclusion of topics #4, #6, #9, #10, #11, #16, #18, and #19, all of which have a combined weight greater than 0.5, is a vital part of this process. These topics are not aligned with the study’s core focus on the uncertainties surrounding central bank policies in a highly dollarized economic context. By meticulously eliminating these unrelated topics, the research narrows its scope to concentrate solely on the relevant narrative text data pertaining to monetary policy, economic indicators, and financial dynamics specific to Cambodia. This targeted approach not only enhances the precision of the derived measures of policy uncertainty but also ensures that the analysis is finely tuned to the unique economic phenomena under investigation in the Cambodian context.
The filtering process for the second stage of the research is executed through a well-defined pipeline, aiming to refine the analysis by excluding specific unrelated topics. Here’s a cohesive description of the process:
Loading DataFrames: The pipeline begins by loading the document-topic distributions from the specified file,
LDA_model(1)_k(20)-doc_topic_dists.parquet.Evaluating Columns: An expression is evaluated to calculate the combined weight of the irrelevant topics (topics #4, #6, #9, #10, #11, #16, #18, and #19). This combined weight is stored in a new column named
topic_irrelevant.Selecting Columns: The pipeline then selects the columns
idandtopic_irrelevant, retaining only the necessary information for the subsequent steps.Merging DataFrames: The selected columns are merged with the tokenized training data from the file
khmer_tokenized/train.parquet, using theidcolumn as the key.Filtering and Sampling Data: Finally, the pipeline filters the data based on the condition that the combined weight of the irrelevant topics (
topic_irrelevant) is less than 0.5. The filtered data is then saved to the specified directory,datasets/processed/topic_noprior_filtered, with filenamestrain.parquetfor the retained data anddiscard.parquetfor the discarded data.
This pipeline ensures a systematic and efficient approach to filtering out unrelated topics, aligning the analysis with the specific focus on central bank policy uncertainty in Cambodia’s highly dollarized economy. By doing so, it enhances the precision and relevance of the study.
You can run the pipeline by executing the following command:
!nbcpu +workflow=nbcpu tasks='[nbcpu-datasets_noprior_filter]' mode=__info__
Show code cell output
[2023-08-15 18:09:22,136][hyfi.joblib.joblib][INFO] - initialized batcher with <hyfi.joblib.batch.batcher.Batcher object at 0x7f43c006d430>
[2023-08-15 18:09:22,136][hyfi.main.config][INFO] - HyFi project [nbcpu] initialized
[2023-08-15 18:09:22,328][hyfi.main.main][INFO] - The HyFI config is not instantiatable, running HyFI task with the config
[2023-08-15 18:09:23,160][hyfi.joblib.joblib][INFO] - initialized batcher with <hyfi.joblib.batch.batcher.Batcher object at 0x7f43902abb50>
[2023-08-15 18:09:24,357][hyfi.workflow.workflow][INFO] - Running task [nbcpu-datasets_noprior_filter] with [run={} verbose=False uses='nbcpu-datasets_noprior_filter']
[2023-08-15 18:09:24,379][hyfi.task.task][INFO] - Running 1 pipeline(s)
[2023-08-15 18:09:24,379][hyfi.task.task][INFO] - Running pipeline: nbcpu-datasets_noprior_filter
[2023-08-15 18:09:24,389][hyfi.task.task][INFO] - Applying 5 pipes: [{'_target_': 'hyfi.utils.datasets.load.DSLoad.load_dataframes', 'data_files': '/home/yjlee/workspace/projects/nbcpu/workspace/nbcpu-topic_noprior/model/outputs/LDA_model(1)_k(20)-doc_topic_dists.parquet', 'data_dir': None, 'filetype': None, 'split': None, 'concatenate': False, 'ignore_index': False, 'use_cached': False, 'verbose': True}, {'_target_': 'hyfi.utils.datasets.basic.DSBasic.dataframe_eval_columns', 'expressions': {'topic_irrelevant': 'topic9 + topic10 + topic11 + topic6 + topic16 + topic18 + topic19 + topic4'}, 'engine': 'python', 'verbose': True}, {'_target_': 'hyfi.utils.datasets.basic.DSBasic.dataframe_select_columns', 'columns': ['id', 'topic_irrelevant'], 'verbose': True}, {'_target_': 'hyfi.utils.datasets.combine.DSCombine.merge_dataframes', 'right': '/home/yjlee/workspace/projects/nbcpu/workspace/datasets/processed/khmer_tokenized/train.parquet', 'how': 'inner', 'on': 'id', 'left_on': None, 'right_on': None, 'left_index': False, 'right_index': False, 'sort': False, 'suffixes': ['_x', '_y'], 'copy': True, 'indicator': False, 'validate': None, 'verbose': True}, {'_target_': 'hyfi.utils.datasets.slice.DSSlice.filter_and_sample_data', 'queries': ['topic_irrelevant < 0.5'], 'sample_size': None, 'sample_seed': 42, 'output_dir': '/home/yjlee/workspace/projects/nbcpu/workspace/datasets/processed/topic_noprior_filtered', 'sample_filename': None, 'train_filename': 'train.parquet', 'discard_filename': 'discard.parquet', 'returning_data': 'train', 'verbose': True}]
Change directory to /home/yjlee/workspace/projects/nbcpu/workspace
[2023-08-15 18:09:24,393][hyfi.pipeline.config][INFO] - Returning partial function: hyfi.utils.datasets.load.DSLoad.load_dataframes with kwargs: {'_target_': 'hyfi.utils.datasets.load.DSLoad.load_dataframes', 'data_files': '/home/yjlee/workspace/projects/nbcpu/workspace/nbcpu-topic_noprior/model/outputs/LDA_model(1)_k(20)-doc_topic_dists.parquet', 'data_dir': None, 'filetype': None, 'split': None, 'concatenate': False, 'ignore_index': False, 'use_cached': False, 'verbose': True}
[2023-08-15 18:09:24,394][hyfi.composer.composer][INFO] - instantiating hyfi.utils.datasets.load.DSLoad.load_dataframes ...
[2023-08-15 18:09:24,396][hyfi.utils.iolibs][INFO] - Processing [1] files from ['/home/yjlee/workspace/projects/nbcpu/workspace/nbcpu-topic_noprior/model/outputs/LDA_model(1)_k(20)-doc_topic_dists.parquet']
[2023-08-15 18:09:24,396][hyfi.utils.datasets.load][INFO] - Loading data from /home/yjlee/workspace/projects/nbcpu/workspace/nbcpu-topic_noprior/model/outputs/LDA_model(1)_k(20)-doc_topic_dists.parquet
[2023-08-15 18:09:24,419][hyfi.utils.datasets.load][INFO] - >> elapsed time to load data: 0:00:00.022801
[2023-08-15 18:09:24,421][hyfi.pipeline.config][INFO] - Returning partial function: hyfi.utils.datasets.basic.DSBasic.dataframe_eval_columns with kwargs: {'_target_': 'hyfi.utils.datasets.basic.DSBasic.dataframe_eval_columns', 'expressions': {'topic_irrelevant': 'topic9 + topic10 + topic11 + topic6 + topic16 + topic18 + topic19 + topic4'}, 'engine': 'python', 'verbose': True}
[2023-08-15 18:09:24,422][hyfi.composer.composer][INFO] - instantiating hyfi.utils.datasets.basic.DSBasic.dataframe_eval_columns ...
[2023-08-15 18:09:24,423][hyfi.utils.datasets.basic][INFO] - Evaluating column topic_irrelevant
[2023-08-15 18:09:24,431][hyfi.pipeline.config][INFO] - Returning partial function: hyfi.utils.datasets.basic.DSBasic.dataframe_select_columns with kwargs: {'_target_': 'hyfi.utils.datasets.basic.DSBasic.dataframe_select_columns', 'columns': ['id', 'topic_irrelevant'], 'verbose': True}
[2023-08-15 18:09:24,432][hyfi.composer.composer][INFO] - instantiating hyfi.utils.datasets.basic.DSBasic.dataframe_select_columns ...
[2023-08-15 18:09:24,433][hyfi.utils.datasets.basic][INFO] - Selecting columns: ['id', 'topic_irrelevant']
[2023-08-15 18:09:24,438][hyfi.pipeline.config][INFO] - Returning partial function: hyfi.utils.datasets.combine.DSCombine.merge_dataframes with kwargs: {'_target_': 'hyfi.utils.datasets.combine.DSCombine.merge_dataframes', 'right': '/home/yjlee/workspace/projects/nbcpu/workspace/datasets/processed/khmer_tokenized/train.parquet', 'how': 'inner', 'on': 'id', 'left_on': None, 'right_on': None, 'left_index': False, 'right_index': False, 'sort': False, 'suffixes': ['_x', '_y'], 'copy': True, 'indicator': False, 'validate': None, 'verbose': True}
[2023-08-15 18:09:24,439][hyfi.composer.composer][INFO] - instantiating hyfi.utils.datasets.combine.DSCombine.merge_dataframes ...
[2023-08-15 18:09:24,442][hyfi.utils.datasets.combine][INFO] - Merging dataframes
[2023-08-15 18:09:27,926][hyfi.pipeline.config][INFO] - Returning partial function: hyfi.utils.datasets.slice.DSSlice.filter_and_sample_data with kwargs: {'_target_': 'hyfi.utils.datasets.slice.DSSlice.filter_and_sample_data', 'queries': ['topic_irrelevant < 0.5'], 'sample_size': None, 'sample_seed': 42, 'output_dir': '/home/yjlee/workspace/projects/nbcpu/workspace/datasets/processed/topic_noprior_filtered', 'sample_filename': None, 'train_filename': 'train.parquet', 'discard_filename': 'discard.parquet', 'returning_data': 'train', 'verbose': True}
[2023-08-15 18:09:27,927][hyfi.composer.composer][INFO] - instantiating hyfi.utils.datasets.slice.DSSlice.filter_and_sample_data ...
[2023-08-15 18:09:27,946][hyfi.utils.datasets.slice][INFO] - filtering data by topic_irrelevant < 0.5
[2023-08-15 18:09:27,953][hyfi.utils.datasets.slice][INFO] - filtered 12053 documents
[2023-08-15 18:09:27,956][hyfi.utils.datasets.save][INFO] - Saving dataframe to /home/yjlee/workspace/projects/nbcpu/workspace/datasets/processed/topic_noprior_filtered/train.parquet
[2023-08-15 18:09:54,942][hyfi.utils.datasets.save][INFO] - >> elapsed time to save data: 0:00:26.985131
id ... predicates
0 501330943 ... [national, ask, financial, consider, provide, ...
1 501326169 ... [national, prepare, standardised, common, fina...
2 501325554 ... [national, prepare, standardised, common, fina...
3 501322478 ... [national, nbc, sign, chinese, international, ...
4 501321914 ... [average, supply, drop, significantly, may, lo...
[5 rows x 12 columns]
[2023-08-15 18:09:54,976][hyfi.utils.datasets.save][INFO] - Saving dataframe to /home/yjlee/workspace/projects/nbcpu/workspace/datasets/processed/topic_noprior_filtered/discard.parquet
[2023-08-15 18:10:06,284][hyfi.utils.datasets.save][INFO] - >> elapsed time to save data: 0:00:11.307363
id ... predicates
25 501269004 ... [ឧបការីទេសាភិបាលធនាគារជាតិនៃកម្ពុជាមានប្រស...
50 501174257 ... [new, 'atmanirbhar, prime, promote, foreign, r...
51 501172186 ... [first, serve, external, unique, couple, atman...
72 501191238 ... [national, nbc, united, organise, nbc, annual,...
103 501011030 ... [new, afp, -us, send, specialist, commentary, ...
[5 rows x 12 columns]
[2023-08-15 18:10:06,302][hyfi.utils.datasets.slice][INFO] - Created 0 samples, 27594 train samples, and 12053 discard samples
Change directory back to /raid/cis/yjlee/workspace/logs/hydra/nbcpu/2023-08-15/2023-08-15_18-09-21
[2023-08-15 18:10:06,507][hyfi.task.task][INFO] - >> elapsed time for the task with 1 pipelines: 0:00:42.127645