Data#
This section delineates the meticulous process of gathering, filtering, and analyzing articles from two major Cambodian news outlets. The resulting dataset, rich in content and chronological depth, forms the foundation for a comprehensive exploration of central bank policy uncertainty in Cambodia’s highly dollarized economy.
Data Sources#
The research draws upon articles from two major Cambodian news outlets: Khmer Times and Phnom Penh Post. These platforms were selected for their extensive coverage of economic and financial matters in Cambodia, including the country’s monetary policy.
Khmer Times#
Khmer Times, a prominent English language newspaper in Cambodia, offers a broad spectrum of news, encompassing domestic and international affairs, politics, business, lifestyle, and culture. Its comprehensive reporting on economic issues makes it a valuable source for this research.
Phnom Penh Post#
The Phnom Penh Post, recognized as Cambodia’s oldest independent newspaper, provides detailed insights into various subjects, including politics, economy, lifestyle, and culture. Its in-depth analysis of domestic economic affairs and policies adds a significant dimension to the dataset.
Data Collection#
The data collection process is methodically designed to gather relevant articles from the selected news outlets, ensuring a rich and focused dataset.
Web Scraping#
Utilizing Python libraries such as BeautifulSoup and requests, articles are extracted from the websites of Khmer Times and Phnom Penh Post. The scraping process retrieves essential details, including the headline, date, and full text of each article.
Keyword Filtering#
To maintain relevance to the research objectives, the dataset is filtered using specific keywords related to economic policy, such as “National Bank of Cambodia,” “monetary policy,” “exchange rate,” and more. This step refines the dataset to include only articles pertinent to central bank policy uncertainty.
Time Frame#
The research considers articles published between January 1, 2014, and July 31, 2023. This defined time frame enables a chronological analysis of policy uncertainty, capturing its evolution over nearly a decade.
Exploratory Data Analysis#
The initial collection yielded 40,002 articles, which after preprocessing, resulted in a final dataset of 39,632 articles.
Yearly Distribution#
The dataset’s yearly distribution reveals insightful patterns:
2014: Starting with 2,047 articles, averaging 3,345 words each.
2015-2018: A steady growth in articles, peaking at 3,530 in 2018, with average lengths oscillating between 3,162 and 3,486 words.
2019-2020: Continued expansion, culminating in 4,688 articles in 2020, maintaining an average length around 3,400 words.
2021-2022: A marked surge, with 5,493 and 6,866 articles in consecutive years, though the average length slightly recedes to approximately 3,100 words.
2023: The partial year includes 3,750 articles, averaging 3,255 words each.
Overall Trends#
Number of Articles: The dataset exhibits a consistent growth in the number of articles, indicative of an escalating interest in subjects related to uncertainty, economics, and central bank policy in Cambodia.
Average Length: Despite minor fluctuations, the average length of the articles remains relatively stable across the years, with an overall mean of 3,247 words.
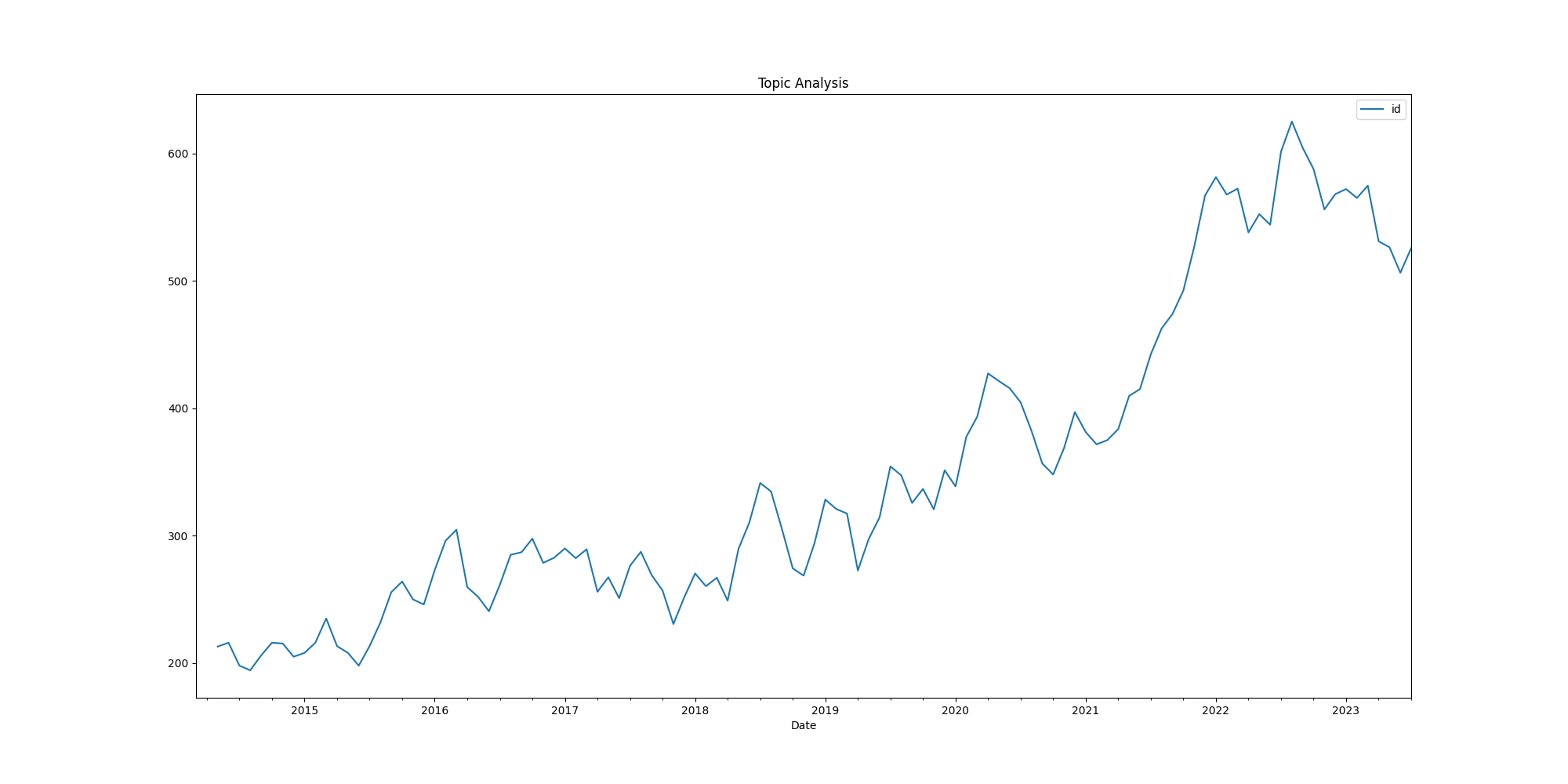
Fig. 1 Number of articles over time#